K-means (K-means clustering) More...


Go to the source code of this file.
Classes | |
| struct | _VlKMeans |
| K-means quantizer. More... | |
Typedefs | |
| typedef struct _VlKMeans | VlKMeans |
| K-means quantizer. | |
| typedef enum _VlKMeansAlgorithm | VlKMeansAlgorithm |
| K-means algorithms. | |
| typedef enum _VlKMeansInitialization | VlKMeansInitialization |
| K-means initialization algorithms. | |
Enumerations | |
| enum | _VlKMeansAlgorithm { VlKMeansLloyd, VlKMeansElkan, VlKMeansANN } |
| K-means algorithms. More... | |
| enum | _VlKMeansInitialization { VlKMeansRandomSelection, VlKMeansPlusPlus } |
| K-means initialization algorithms. More... | |
Functions | |
Create and destroy | |
| VL_EXPORT VlKMeans * | vl_kmeans_new (vl_type dataType, VlVectorComparisonType distance) |
| Create a new KMeans object. | |
| VL_EXPORT VlKMeans * | vl_kmeans_new_copy (VlKMeans const *kmeans) |
| Create a new KMeans object by copy. | |
| VL_EXPORT void | vl_kmeans_delete (VlKMeans *self) |
| Deletes a KMeans object. | |
Basic data processing | |
| VL_EXPORT void | vl_kmeans_reset (VlKMeans *self) |
| Reset state. | |
| VL_EXPORT double | vl_kmeans_cluster (VlKMeans *self, void const *data, vl_size dimension, vl_size numData, vl_size numCenters) |
| VL_EXPORT void | vl_kmeans_quantize (VlKMeans *self, vl_uint32 *assignments, void *distances, void const *data, vl_size numData) |
| VL_EXPORT void | vl_kmeans_quantize_ANN (VlKMeans *self, vl_uint32 *assignments, void *distances, void const *data, vl_size numData, vl_size iteration) |
Advanced data processing | |
| VL_EXPORT void | vl_kmeans_set_centers (VlKMeans *self, void const *centers, vl_size dimension, vl_size numCenters) |
| VL_EXPORT void | vl_kmeans_init_centers_with_rand_data (VlKMeans *self, void const *data, vl_size dimensions, vl_size numData, vl_size numCenters) |
| VL_EXPORT void | vl_kmeans_init_centers_plus_plus (VlKMeans *self, void const *data, vl_size dimensions, vl_size numData, vl_size numCenters) |
| VL_EXPORT double | vl_kmeans_refine_centers (VlKMeans *self, void const *data, vl_size numData) |
Retrieve data and parameters | |
| VL_INLINE vl_type | vl_kmeans_get_data_type (VlKMeans const *self) |
| Get data type. | |
| VL_INLINE VlVectorComparisonType | vl_kmeans_get_distance (VlKMeans const *self) |
| Get data type. | |
| VL_INLINE VlKMeansAlgorithm | vl_kmeans_get_algorithm (VlKMeans const *self) |
| Get K-means algorithm. | |
| VL_INLINE VlKMeansInitialization | vl_kmeans_get_initialization (VlKMeans const *self) |
| Get K-means initialization algorithm. | |
| VL_INLINE vl_size | vl_kmeans_get_num_repetitions (VlKMeans const *self) |
| Get maximum number of repetitions. | |
| VL_INLINE vl_size | vl_kmeans_get_dimension (VlKMeans const *self) |
| Get data dimension. | |
| VL_INLINE vl_size | vl_kmeans_get_num_centers (VlKMeans const *self) |
| Get the number of centers (K) | |
| VL_INLINE int | vl_kmeans_get_verbosity (VlKMeans const *self) |
| Get verbosity level. | |
| VL_INLINE vl_size | vl_kmeans_get_max_num_iterations (VlKMeans const *self) |
| Get maximum number of iterations. | |
| VL_INLINE double | vl_kmeans_get_min_energy_variation (VlKMeans const *self) |
| Get the minimum relative energy variation for convergence. | |
| VL_INLINE vl_size | vl_kmeans_get_max_num_comparisons (VlKMeans const *self) |
| Get the maximum number of comparisons in the KD-forest ANN algorithm. | |
| VL_INLINE vl_size | vl_kmeans_get_num_trees (VlKMeans const *self) |
| VL_INLINE double | vl_kmeans_get_energy (VlKMeans const *self) |
| Get the number energy of the current fit. | |
| VL_INLINE void const * | vl_kmeans_get_centers (VlKMeans const *self) |
| Get centers. | |
Set parameters | |
| VL_INLINE void | vl_kmeans_set_algorithm (VlKMeans *self, VlKMeansAlgorithm algorithm) |
| Set K-means algorithm. | |
| VL_INLINE void | vl_kmeans_set_initialization (VlKMeans *self, VlKMeansInitialization initialization) |
| Set K-means initialization algorithm. | |
| VL_INLINE void | vl_kmeans_set_num_repetitions (VlKMeans *self, vl_size numRepetitions) |
| Set maximum number of repetitions. | |
| VL_INLINE void | vl_kmeans_set_max_num_iterations (VlKMeans *self, vl_size maxNumIterations) |
| Set maximum number of iterations. | |
| VL_INLINE void | vl_kmeans_set_min_energy_variation (VlKMeans *self, double minEnergyVariation) |
| Set the maximum relative energy variation for convergence. | |
| VL_INLINE void | vl_kmeans_set_verbosity (VlKMeans *self, int verbosity) |
| Set verbosity level. | |
| VL_INLINE void | vl_kmeans_set_max_num_comparisons (VlKMeans *self, vl_size maxNumComparisons) |
| Set maximum number of comparisons in ANN-KD-Tree. | |
| VL_INLINE void | vl_kmeans_set_num_trees (VlKMeans *self, vl_size numTrees) |
| Set the number of trees in the KD-forest ANN algorithm. | |
Detailed Description
K-means (K-means clustering)
Definition in file kmeans.h.
Typedef Documentation
K-means quantizer.
------------------------------------------------------------------
| typedef enum _VlKMeansAlgorithm VlKMeansAlgorithm |
K-means algorithms.
| typedef enum _VlKMeansInitialization VlKMeansInitialization |
K-means initialization algorithms.
Enumeration Type Documentation
| enum _VlKMeansAlgorithm |
Function Documentation
| VL_EXPORT double vl_kmeans_cluster | ( | VlKMeans * | self, |
| void const * | data, | ||
| vl_size | dimension, | ||
| vl_size | numData, | ||
| vl_size | numCenters | ||
| ) |
| VL_EXPORT void vl_kmeans_delete | ( | VlKMeans * | self | ) |
Deletes a KMeans object.
------------------------------------------------------------------
- Parameters:
-
self KMeans object instance.
The function deletes the KMeans object instance created by vl_kmeans_new.
| VL_INLINE VlKMeansAlgorithm vl_kmeans_get_algorithm | ( | VlKMeans const * | self | ) |
| VL_INLINE void const * vl_kmeans_get_centers | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_type vl_kmeans_get_data_type | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_size vl_kmeans_get_dimension | ( | VlKMeans const * | self | ) |
| VL_INLINE VlVectorComparisonType vl_kmeans_get_distance | ( | VlKMeans const * | self | ) |
| VL_INLINE double vl_kmeans_get_energy | ( | VlKMeans const * | self | ) |
| VL_INLINE VlKMeansInitialization vl_kmeans_get_initialization | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_size vl_kmeans_get_max_num_comparisons | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_size vl_kmeans_get_max_num_iterations | ( | VlKMeans const * | self | ) |
| VL_INLINE double vl_kmeans_get_min_energy_variation | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_size vl_kmeans_get_num_centers | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_size vl_kmeans_get_num_repetitions | ( | VlKMeans const * | self | ) |
| VL_INLINE vl_size vl_kmeans_get_num_trees | ( | VlKMeans const * | self | ) |
| VL_INLINE int vl_kmeans_get_verbosity | ( | VlKMeans const * | self | ) |
| VL_EXPORT void vl_kmeans_init_centers_plus_plus | ( | VlKMeans * | self, |
| void const * | data, | ||
| vl_size | dimensions, | ||
| vl_size | numData, | ||
| vl_size | numCenters | ||
| ) |
| VL_EXPORT void vl_kmeans_init_centers_with_rand_data | ( | VlKMeans * | self, |
| void const * | data, | ||
| vl_size | dimensions, | ||
| vl_size | numData, | ||
| vl_size | numCenters | ||
| ) |
| VL_EXPORT VlKMeans* vl_kmeans_new | ( | vl_type | dataType, |
| VlVectorComparisonType | distance | ||
| ) |
Create a new KMeans object.
------------------------------------------------------------------
- Parameters:
-
dataType type of data (VL_TYPE_FLOAT or VL_TYPE_DOUBLE) distance distance.
- Returns:
- new KMeans object instance.
| VL_EXPORT VlKMeans* vl_kmeans_new_copy | ( | VlKMeans const * | kmeans | ) |
| VL_EXPORT void vl_kmeans_quantize | ( | VlKMeans * | self, |
| vl_uint32 * | assignments, | ||
| void * | distances, | ||
| void const * | data, | ||
| vl_size | numData | ||
| ) |
| VL_EXPORT void vl_kmeans_quantize_ANN | ( | VlKMeans * | self, |
| vl_uint32 * | assignments, | ||
| void * | distances, | ||
| void const * | data, | ||
| vl_size | numData, | ||
| vl_size | iteration | ||
| ) |
| VL_EXPORT double vl_kmeans_refine_centers | ( | VlKMeans * | self, |
| void const * | data, | ||
| vl_size | numData | ||
| ) |
| VL_EXPORT void vl_kmeans_reset | ( | VlKMeans * | self | ) |
Reset state.
$ of the points to the centers such that the sum of distances
\[ E(,,,q_1,,q_n) = {i=1}^n \| - {q_i} \|_p^p \]
is minimized. $K$-means is obtained for the case $p=2$ ($l^2$ norm), because in this case the optimal centers are the means of the input vectors assigned to them. Here the generalization $p=1$ ($l^1$ norm) will also be considered.
Up to normalization, the K-means objective $E$ is also the average reconstruction error if the original points are approximated with the cluster centers. Thus K-means is used not only to group the input points into cluster, but also to `quantize` their values.
K-means is widely used in computer vision, for example in the construction of vocabularies of visual features (visual words). In these applications the number $n$ of points to cluster and/or the number $K$ of clusters is often large. Unfortunately, minimizing the objective $E$ is in general a difficult combinatorial problem, so locally optimal or approximated solutions are sought instead.
The basic K-means algorithm alternate between re-estimating the centers and the assignments (Lloyd's algorithm). Combined with a good initialization strategy (Initialization methods) and, potentially, by re-running the optimization from a number of randomized starting states, this algorithm may attain satisfactory solutions in practice.
However, despite its simplicity, Lloyd's algorithm is often too slow. A good replacement is Elkan's algorithm (Elkan's algorithm), which uses the triangular inequality to cut down significantly the cost of Lloyd's algorithm. Since this algorithm is otherwise equivalent, it should often be preferred.
For very large problems (millions of point to clusters and hundreds, thousands, or more clusters to find), even Elkan's algorithm is not sufficiently fast. In these cases, one can resort to a variant of Lloyd's algorithm that uses an approximated nearest neighbors routine (ANN algorithm).
Initialization methods
All the $K$-means algorithms considered here find locally optimal solutions; as such the way they are initialized is important. kmeans.h supports the following initialization algorithms:
- Random data samples
The simplest initialization method is to sample $K$ points at random from the input data and use them as initial values for the cluster centers.
- K-means++
[arthur07k-means]} proposes a randomized initialization of the centers which improves upon random selection. The first center $$ is selected at random from the data points $, , $ and the distance from this center to all points $\| - \|_p^p$ is computed. Then the second center $$ is selected at random from the data points with probability proportional to the distance. The procedure is repeated to obtain the other centers by using the minimum distance to the centers collected so far.
Lloyd's algorithm
The most common K-means method is Lloyd's algorithm [lloyd82least]}. This algorithm is based on the observation that, while jointly optimizing clusters and assignment is difficult, optimizing one given the other is easy. Lloyd's algorithm alternates the steps:
1. **Quantization.** Each point $$ is reassigned to the center ${q_j}$ closer to it. This requires finding for each point the closest among $K$ other points, which is potentially slow. 2. **Center estimation.** Each center $$ is updated to minimize its average distances to the points assigned to it. It is easy to show that the best center is the mean or median of the points, respectively if the $l^2$ or $l^1$ norm is considered.
A naive implementation of the assignment step requires $O(dnK)$ operations, where $d$ is the dimensionality of the data, $n$ the number of data points, and $K$ the number of centers. Updating the centers is much cheaper: $O(dn)$ operations suffice to compute the $K$ means and a slightly higher cost is required for the medians. Clearly, the bottleneck is the assignment computation, and this is what the other K-means algorithm try to improve.
During the iterations, it can happen that a cluster becomes empty. In this case, K-means automatically **“restarts” the cluster** center by selecting a training point at random.
Elkan's algorithm
Elkan's algorithm [elkan03using]} is a variation of Lloyd alternate optimization algorithm (Lloyd's algorithm) that uses the triangular inequality to avoid many distance calculations when assigning points to clusters. While much faster than Lloyd, Elkan's method uses storage proportional to the umber of clusters by data points, which makes it unpractical for a very large number of clusters.
The idea of this algorithm is that, if a center update does not move them much, then most of the point-to-center computations can be avoided when the point-to-center assignments are recomputed. To detect which distances need evaluation, the triangular inequality is used to lower and upper bound distances after a center update.
Elkan algorithms uses two key observations. First, one has
\[ \| - {q_i}\|_p \| - {q_i}\|_p / 2 \| - {q_i}\|_p \| - \|_p. \]
Thus if the distance between $$ and its current center ${q_i}$ is less than half the distance of the center ${q_i}$ to another center $$, then $$ can be skipped when the new assignment for $$ is searched. Checking this requires keeping track of all the inter-center distances, but centers are typically a small fraction of the training data, so overall this can be a significant saving. In particular, if this condition is satisfied for all the centers $ = {q_i}$, the point $$ can be skipped completely. Furthermore, the condition can be tested also based on an upper bound $UB_i$ of $\| - {q_i}\|_p$.
Second, if a center $$ is updated to ${}$, then the new distance from $$ to ${}$ is bounded from below and above by
\[ \| - \|_p - \|bc - \|_p \| - {}\|_p \| - {}\|_p + \| + {}\|_p. \]
This allows to maintain an upper bound on the distance of $$ to its current center ${q_i}$ and a lower bound to any other center $$:
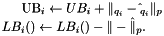
Thus the K-means algorithm becomes:
1. **Initialization.** Compute $LB_i() = \| - \|_p$ for all points and centers. Find the current assignments $q_i$ and bounds $UB_i$ by finding the closest centers to each point: $UB_i = {} LB_i()$. 2. **Center estimation.** 1. Recompute all the centers based on the new means; call the updated version ${}$. 2. Update all the bounds based on the distance $\| - \|_p$ as explained above. 3. Set $ $ for all the centers and go to the next iteration. 3. **Quantization.** 1. Skip any point $$ such that $UB_i {1}{2} \|{q_i} - \|_p$ for all centers $ = {q_i}$. 2. For each remaining point $$ and center $ = {q_i}$: 1. Skip $$ if \[ UB_i {1}{2} \| {q_i} - \| {or} UB_i LB_i(). \] The first condition reflects the first observation above; the second uses the bounds to decide if $$ can be closer than the current center ${q_i}$ to the point $$. If the center cannot be skipped, continue as follows. 3. Skip $$ if the condition above is satisfied after making the upper bound tight: \[ UB_i = LB_i({q_i}) = \| - {q_i} \|_p. \] Note that the latter calculation can be done only once for $$. If the center cannot be skipped still, continue as follows. 4. Tighten the lower bound too: \[ LB_i() = \| - \|_p. \] At this point both $UB_i$ and $LB_i()$ are tight. If $LB_i < UB_i$, then the point $$ should be reassigned to $$. Update $q_i$ to the index of center $$ and reset $UB_i = LB_i()$.
ANN algorithm
The *Approximate Nearest Neighbor* (ANN) K-means algorithm [beis97shape]} [silpa-anan08optimised]} [muja09fast]} is a variant of Lloyd's algorithm (Lloyd's algorithm) uses a best-bin-first randomized KD-tree algorithm to approximately (and quickly) find the closest cluster center to each point. The KD-tree implementation is based on KD-trees and forests.
The algorithm can be summarized as follows:
1. **Quantization.** Each point $$ is reassigned to the center ${q_j}$ closer to it. This starts by indexing the $K$ centers by a KD-tree and then using the latter to quickly find the closest center for every training point. The search is approximated to further improve speed. This opens up the possibility that a data point may receive an assignment that is *worse* than the current one. This is avoided by checking that the new assignment estimated by using ANN is an improvement; otherwise the old assignment is kept. 2. **Center estimation.** Each center $$ is updated to minimize its average distances to the points assigned to it. It is easy to show that the best center is the mean or median of the points, respectively if the $l^2$ or $l^1$ norm is considered.
The key is to trade-off carefully the speedup obtained by using the ANN algorithm and the loss in accuracy when retrieving neighbors. Due to the curse of dimensionality, KD-trees become less effective for higher dimensional data, so that the search cost, which in the best case is logarithmic with this data structure, may become effectively linear. This is somehow mitigated by the fact that new a new KD-tree is computed at each iteration, reducing the likelihood that points may get stuck with sub-optimal assignments.
Experiments with the quantization of 128-dimensional SIFT features show that the ANN algorithm may use one quarter of the comparisons of Elkan's while retaining a similar solution accuracy. ------------------------------------------------------------------ The function reset the state of the KMeans object. It deletes any stored centers, releasing the corresponding memory. This cancels the effect of seeding or setting the centers, but does not change the other configuration parameters.
| VL_INLINE void vl_kmeans_set_algorithm | ( | VlKMeans * | self, |
| VlKMeansAlgorithm | algorithm | ||
| ) |
| VL_EXPORT void vl_kmeans_set_centers | ( | VlKMeans * | self, |
| void const * | centers, | ||
| vl_size | dimension, | ||
| vl_size | numCenters | ||
| ) |
| VL_INLINE void vl_kmeans_set_initialization | ( | VlKMeans * | self, |
| VlKMeansInitialization | initialization | ||
| ) |
| VL_INLINE void vl_kmeans_set_max_num_comparisons | ( | VlKMeans * | self, |
| vl_size | maxNumComparisons | ||
| ) |
| VL_INLINE void vl_kmeans_set_max_num_iterations | ( | VlKMeans * | self, |
| vl_size | maxNumIterations | ||
| ) |
| VL_INLINE void vl_kmeans_set_min_energy_variation | ( | VlKMeans * | self, |
| double | minEnergyVariation | ||
| ) |
Set the maximum relative energy variation for convergence.
- Parameters:
-
self KMeans object instance. minEnergyVariation maximum number of repetitions. The variation cannot be negative.
The relative energy variation is calculated after the $t$-th update to the parameters as:
\[ = {E_{t-1} - E_t}{E_0 - E_t} \]
Note that this quantitiy is non-negative since $E_{t+1} E_t$. Hence, $$ is the improvement to the energy made in the last iteration compared to the total improvement so far. The algorithm stops if this value is less or equal than minEnergyVariation.
This test is applied only to the LLoyd and ANN algorithms.
| VL_INLINE void vl_kmeans_set_num_repetitions | ( | VlKMeans * | self, |
| vl_size | numRepetitions | ||
| ) |
| VL_INLINE void vl_kmeans_set_num_trees | ( | VlKMeans * | self, |
| vl_size | numTrees | ||
| ) |
| VL_INLINE void vl_kmeans_set_verbosity | ( | VlKMeans * | self, |
| int | verbosity | ||
| ) |