Public Member Functions |
| template<int N, class B1 , class B2 , class B3 > |
| void | add_mJ (const Vector< N, Precision, B1 > &m, const Matrix< Size, N, Precision, B2 > &J, const Matrix< N, N, Precision, B3 > &invcov) |
| template<class B2 > |
| void | add_mJ (Precision m, const Vector< Size, Precision, B2 > &J, Precision weight=1) |
| template<class B2 > |
| void | add_prior (const Matrix< Size, Size, Precision, B2 > &m) |
| template<class B2 > |
| void | add_prior (const Vector< Size, Precision, B2 > &v) |
| void | add_prior (Precision val) |
| void | clear () |
| | Clear all the measurements and apply a constant regularisation term.
|
| void | compute () |
const Matrix< Size, Size,
Precision > & | get_C_inv () const |
| | Returns the inverse covariance matrix.
|
| Matrix< Size, Size, Precision > & | get_C_inv () |
| | Returns the inverse covariance matrix.
|
const Decomposition< Size,
Precision > & | get_decomposition () const |
| | Return the decomposition object used to compute 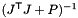 . .
|
| Decomposition< Size, Precision > & | get_decomposition () |
| | Return the decomposition object used to compute .
|
| const Vector< Size, Precision > & | get_mu () const |
| | Returns the update. With no prior, this is the result of 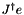 . .
|
| Vector< Size, Precision > & | get_mu () |
| | Returns the update. With no prior, this is the result of .
|
| const Vector< Size, Precision > & | get_vector () const |
| | Returns the vector 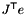 . .
|
| Vector< Size, Precision > & | get_vector () |
| | Returns the vector .
|
| void | operator+= (const WLS &meas) |
| | WLS (int size=0) |
| | Default constructor or construct with the number of dimensions for the Dynamic case.
|
Private Member Functions |
| int | operator= (WLS ©of) |
| | WLS (WLS ©of) |
Private Attributes |
| Matrix< Size, Size, Precision > | my_C_inv |
| Decomposition< Size, Precision > | my_decomposition |
| Vector< Size, Precision > | my_mu |
| Vector< Size, Precision > | my_vector |
Performs Gauss-Newton weighted least squares computation.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| TooN::WLS< Size, Precision, Decomposition >::WLS |
( |
int |
size = 0 |
) |
[inline] |
Default constructor or construct with the number of dimensions for the Dynamic case.
Definition at line 52 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
template<int N, class B1 , class B2 , class B3 >
| void TooN::WLS< Size, Precision, Decomposition >::add_mJ |
( |
const Vector< N, Precision, B1 > & |
m, |
|
|
const Matrix< Size, N, Precision, B2 > & |
J, |
|
|
const Matrix< N, N, Precision, B3 > & |
invcov | |
|
) |
| | [inline] |
Add multiple measurements at once (much more efficiently)
- Parameters:
-
| m | The measurements to add |
| J | The Jacobian matrix 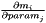 |
| invcov | The inverse covariance of the measurement values |
Definition at line 117 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
template<class B2 >
| void TooN::WLS< Size, Precision, Decomposition >::add_prior |
( |
const Matrix< Size, Size, Precision, B2 > & |
m |
) |
[inline] |
Applies a whole-matrix regularisation term. This is the same as adding the 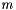 to the inverse covariance matrix.
to the inverse covariance matrix.
- Parameters:
-
| m | The inverse covariance matrix to add |
Definition at line 91 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
template<class B2 >
| void TooN::WLS< Size, Precision, Decomposition >::add_prior |
( |
const Vector< Size, Precision, B2 > & |
v |
) |
[inline] |
Applies a regularisation term with a different strength for each parameter value. Equates to a prior that says all the parameters are zero with 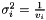 .
.
- Parameters:
-
Definition at line 80 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| void TooN::WLS< Size, Precision, Decomposition >::add_prior |
( |
Precision |
val |
) |
[inline] |
Applies a constant regularisation term. Equates to a prior that says all the parameters are zero with 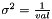 .
.
- Parameters:
-
| val | The strength of the prior |
Definition at line 70 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| void TooN::WLS< Size, Precision, Decomposition >::clear |
( |
|
) |
[inline] |
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| void TooN::WLS< Size, Precision, Decomposition >::compute |
( |
|
) |
[inline] |
Process all the measurements and compute the weighted least squares set of parameter values stores the result internally which can then be accessed by calling get_mu()
Definition at line 128 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| const Decomposition<Size,Precision>& TooN::WLS< Size, Precision, Decomposition >::get_decomposition |
( |
|
) |
const [inline] |
Return the decomposition object used to compute .
Definition at line 155 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| const Vector<Size,Precision>& TooN::WLS< Size, Precision, Decomposition >::get_mu |
( |
|
) |
const [inline] |
Returns the update. With no prior, this is the result of .
Definition at line 151 of file wls.h.
template<int Size = Dynamic, class Precision = double, template< int Size, class Precision > class Decomposition = Cholesky>
| Vector<Size,Precision>& TooN::WLS< Size, Precision, Decomposition >::get_mu |
( |
|
) |
[inline] |
Returns the update. With no prior, this is the result of .
Definition at line 150 of file wls.h.